iTalk2Learn partners, Sail, explain how they evaluate automatic speech recognition systems
Word Error Rate
The standard measurement to assess the performance of an automatic speech recognition (ASR) system is the so-called word-error-rate (WER, (Jelinek, 1997)). WER is a minimum edit-distance measure produced by applying a dynamic alignment between the output of the ASR system and a reference transcript (similar to the Levenstein distance (Manning, C., Schütze, H. (1999))
In the alignment process, three types of errors can be distinguished:
- substitutions (sub)
- deletions (del) and
- insertions (ins)
SUBstitution-errors concern words which were transcribed wrongly (Word-A in the reference was transcribed as Word-B), whereas INSertions and DELetions concern words which were transcribed in addition to reference words or words omitted during transcription. These errors can be assigned different weights for the comparison process (according to the requirements of the domain some types of errors may be more/less costly). In order to calculate the WER, the recognizer is used to transcribe audio corresponding to the test set. The resulting transcript is then compared to the true transcription provided as reference. Table 1 below provides an example of an alignment produced from actual iTalk2Learn test data. The reference is marked as (REF). The output produced by ASR system as (HYP). The types of errors used for WER calculation are listed as SUB, INS and DEL.
| REF | two | sections | to | make | one | third | *** | and | then | you | have | got | another | two |
| HYP (ASR) | two | sections | to | make | one | there | it’s | and | then | you | **** | our | numbers | two |
| Type of error | SUB | INS | DEL | SUB | SUB |
Table 1 – Alignment and types of errors for test phrase.
The WER is then defined as follows:
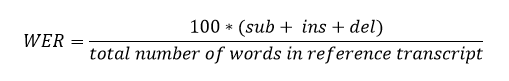
Equation 1 – Word-error-rate (WER) calculation
The above example comparison yields a WER of 38.46%.

However, in our setup the WER alone could be misleading – or only providing a partial picture – as it assigns the same weight to all words involved regardless of their information content (e.g. an article like “the” is regarded to have the same importance as a mathematical term such as “denominator”). Furthermore, compound words and affixes may be scored as errors even though they were actually recognized correctly, e.g. “Beispiel Sammlung” vs “Beispielsammlung” (collection of exercises) in German. Using the compound as reference and the two components as the recognized words would result in two errors: one substitution and one insertion – even though the words were actually recognized correctly.
Whereas WER provides an important measure in determining performance on a word-by-word level and is typically applied to measure progress when developing different acoustic and languages models, it only provides one angle of system performance and can be misleading when viewed in isolation. The primary goals of ASR within iTalk2Learn are to assess children’s use of the correct mathematical terminology and to provide input for emotion classification. Consequently, we are interested primarily in the correct recognition of specific keywords and phrases. The usual measures regarding the detection of keywords are precision and recall (and their harmonic mean called the f-measure). Their particular properties and factors concerning performance evaluation compared to WER will be covered in a future article on this blog.
References
[1] Jelinek, F. (1997) Statistical Methods for Speech Recognition, MIT Press.
[2] Manning, C., Schütze, H. (1999) Foundations of Statistical Natural Language Processing, MIT Press.


